FILE SYSTEM V/S DBMS
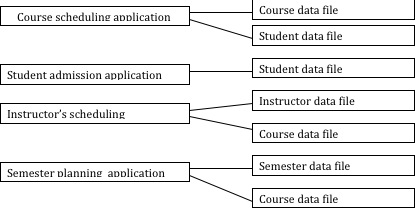
Data processing system is an automated system for processing data of an organization. The conventional data processing approach is to develop a program (or many programs) for each application. This results in one or more data files for each application (figure A). Some of the data may be common between files. However, one application may require the file to be arranged on a particular field, e.g. amount. A major drawback of conventional method is that the storage and access techniques are built into the program. Therefore, though the same data may be required by two applications, the data will have to be stored in to different places because each application depends on the way that the data is stored.
Figure: One to one correspondences between applications and data files.
There are various drawback of the conventional data file processing environment. Some of them are listed below.
a) Data Redundancy: Some data elements like name, address, identification code, are used in various applications. Since data is required by multiple applications, it is stored in multiple data files. In most cases, there is a repetition of data files. This is referred to as data redundancy, and it leads to various other problems.
b) Data Integrity problem: Data redundancy is one reason for problems of data integrity. Since, the same data is stored in different places, if any type of change is made in any file at any place, and if the change is not made in all the places, the university will have different information in different places about the same instructor.
c) Data Availability Constraints: When data is scattered in different files, the availability of information from combination of files is constrained to some extent.
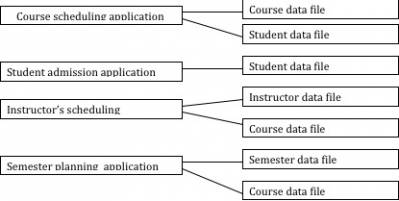 Figure: One to one correspondences between applications and data files.There are various drawback of the conventional data file processing environment. Some of them are listed below.a) Data Redundancy: Some data elements like name, address, identification code, are used in various applications. Since data is required by multiple applications, it is stored in multiple data files. In most cases, there is a repetition of data files. This is referred to as data redundancy, and it leads to various other problems.b) Data Integrity problem: Data redundancy is one reason for problems of data integrity. Since, the same data is stored in different places, if any type of change is made in any file at any place, and if the change is not made in all the places, the university will have different information in different places about the same instructor.c) Data Availability Constraints: When data is scattered in different files, the availability of information from combination of files is constrained to some extent.
Figure: One to one correspondences between applications and data files.There are various drawback of the conventional data file processing environment. Some of them are listed below.a) Data Redundancy: Some data elements like name, address, identification code, are used in various applications. Since data is required by multiple applications, it is stored in multiple data files. In most cases, there is a repetition of data files. This is referred to as data redundancy, and it leads to various other problems.b) Data Integrity problem: Data redundancy is one reason for problems of data integrity. Since, the same data is stored in different places, if any type of change is made in any file at any place, and if the change is not made in all the places, the university will have different information in different places about the same instructor.c) Data Availability Constraints: When data is scattered in different files, the availability of information from combination of files is constrained to some extent.